




- @CLKTOY
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
目录0-前言1-实时计算2-实时计算应用场景2.1-实时智能推荐2.2-实时欺诈检测2.3-舆情分析2.4-复杂事件处理2.5-实时机器学习3-实时计算架构4-实时数仓解决方案0-前言本文分为四个章节介绍实时计算,第一节介绍实时计算出现的原因及概念;第二节介绍实时计算的应用场景;第三节介绍实时计算常见的架构;第四节是实时数仓解决方案。1-实时计算实时计算一般都是针对海量数据进行的,并且要求为秒级。
如何使用hiveSQL提取JSON中的value值0-需求1-Hive自带的json解析函数2-Hive解析json数组3-总结0-需求在Hive中会有很多数据是用Json格式来存储的,如开发人员对APP上的页面进行埋点时,会将多个字段存放在一个json数组中,因此数据平台调用数据时,要对埋点数据进行解析。接下来就聊聊Hive中是如何解析json数据的。1-Hive自带的json解析函数(1)ge
目录0-前言1-TextFile2-SequenceFile3-RCFile4-ORCFile4.1-ORC相比较 RCFile 的优点4.2-ORC的基本结构4.3-ORC的数据类型4.4-ORC 的 ACID 事务的支持4.5-ORC 相关的 Hive 配置5-Parquet5.1-Parquet基本结构5.2-Parquet 的相关配置:5.3-使用Spark引擎时 Parquet 表的压缩
目录1-为什么要做ID-Mapping2-ID-Mapping的核心技术3-总结1-为什么要做ID-Mapping为啥要做ID Mapping?其实技术都是为了解决实际业务问题的。如果没有数据孤岛的问题,也就不会有这波澜壮阔的数字技术发展和改革。举个例子:在 10 多年前的时候,当时IT界都还在做“四库十二金”的项目。就是把一个地区的所有地址给弄干净。这可就费劲了,因为同一个地址有 N 多种写法,
如何使用hiveSQL提取JSON中的value值0-需求1-Hive自带的json解析函数2-Hive解析json数组3-总结0-需求在Hive中会有很多数据是用Json格式来存储的,如开发人员对APP上的页面进行埋点时,会将多个字段存放在一个json数组中,因此数据平台调用数据时,要对埋点数据进行解析。接下来就聊聊Hive中是如何解析json数据的。1-Hive自带的json解析函数(1)ge
目录1- 消费者组的特点2- 消费者组的优势2.1- 高性能2.2- 消费模式灵活2.3- 故障容灾3 小结1- 消费者组的特点这是 kafka 集群的典型部署模式。消费组保证了:一个分区只可以被消费组中的一个消费者所消费一个消费组中的一个消费者可以消费多个分区,例如 C1 消费了 P0, P3。一个消费组中的不同消费者消费的分区一定不会重复,例如:所有消费者一起消费所有的分区,例如 C1 和 C
目录1-实时数仓架构特点1.1-数仓分层明显少于离线数仓1.2-数据存储的多样化1.3-技术难度远高于离线数仓2-实时数仓应用场景3-实时数仓架构3.1-lamdba架构3.2-kappa架构3.3-架构对比1-实时数仓架构特点1.1-数仓分层明显少于离线数仓一般实时数仓主要是公共层的模型层,缩短数据处理时间,保证数据及时性。1.2-数据存储的多样化离线数仓的数据一般存储于hdfs,但是对于实时数
kafka在一个消费者组内设置多个消费者
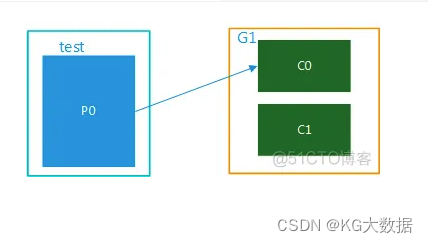
kafka在一个消费者组内设置多个消费者